

Aujourd’hui je vais sortir un article des brouillons suite à 2 articles que j’ai pu lire ces 2 dernières semaines. Le premier qui est en fait l’écoute du podcast de Julien chez Laurent Bourrelly et le second un article de Julien expliquant ce qu’il lui est arrivé en balançant son réseau sur twitter. Donc avant toutes choses et pour que cela soit bien clair pour la suite de l’article, je tiens à préciser que je n’ai absolument rien contre Julien. C’est juste le déclencheur de la reprise d’activité sur ce blog 🙂
L’anonymat, l’allié des réseaux de sites
Monter un réseau de sites et lui donner un minimum de power, cela peut parfois prendre du temps (tout dépend du niveau d’automatisation que vous avez mis en place en amont ET en aval). Le rendre intraçable est une des conditions qui doit être réfléchie avant la création de ce réseau et cela pour différentes raisons :
- Ne pas montrer à Google : « Hey man, t’as vu tous ces sites. Ce sont les miens !! »
- Ne pas montrer à vos concurrents : « Hey men, vous avez vu ces sites. Ce sont les miens !! »
- Eviter que quand votre famille tape votre nom de famille dans un moteur de recherche, elle tombe sur des résultats de whois avec des NDD qui sont parfois assez explicites (vous savez les fameux EMD).
Ainsi pour éviter de se faire tracer, le gestionnaire de réseau doit prendre plusieurs précautions :
- Ne pas mettre ses sites dans GWT (où alors avec des identités différentes, mais bon à éviter quand même)
- Faire attention avec les codes de tracking analytics (que ce soit avec Piwik, GA, …).
- Faire attention avec les codes d’affil et de ads
- Bloquer les bots indésirables via .htaccess
- Prendre des whois anonymes
- Ne pas mettre tous ses sites sur le même serveur. Varier au max les IP
- Varier au max les templates et CMS des sites de son réseau
- Faire attention à certains plugins de CMS (je pense notamment à mainWP, mais il y en a d’autres)
- Faire attention aux fichiers que vous incluez sur vos sites (js, css). C’est parfois un aspect qui est négligé et qui permet de remonter un réseau, comme nous pourrons le voir par la suite.
Comment réussir à identifier et obtenir un réseau
Il existe plusieurs façons pour identifier un réseau de sites. En fonction des précautions que le gestionnaire du réseau aura prises, certaines de ces solutions seront inefficaces.
Le Whois
Le whois d’un nom de domaine recense les informations sur les coordonnées de l’hébergeur, du propriétaire, du contact technique … . Sur linux la commande « whois » permet d’obtenir ces informations. Mais il existe une multitude de sites qui permettent d’obtenir ces informations, comme par exemple : http://whois.domaintools.com/
Pour obtenir la liste des sites appartenant à une personne donnée, un footprint comme celui-ci fera l’affaire :
"Nom" + "Adresse" + site:whois.domaintools.com
Les sites hébergés sur la même adresse IP
Comme nous l’évoquions précédemment, certains sites sont hébergés sur un serveur dédié avec la même adresse IP. Pour cela, je vous renvoi sur un POC que j’avais publié en 2011 : https://www.renardudezert.com/2011/02/14/lopportunite-souvent-negligee.html
Les fichiers « inclus »
C’est ce dernier point qui sera le plus souvent négligé lors de l’élaboration d’un réseau. Jusqu’il y a peu de temps, il n’existait pas de moteurs qui permettaient d’effectuer des recherches dans le code source des pages qu’ils avaient crawlées. Mais avec l’explosion et la « mode » du Big Data de ces dernières années, certains moteurs se révèlent très efficaces dans ce domaine. Je vais vous parler de nerdyData, qui lorsqu’il était sorti s’annonçait déjà prometteur (cf ce RT).
Pour en revenir au cas de Julien, il y a bien sur l’effet twitter qui est indéniable. Mais si la personne qui a balancé le réseau était un peu plus maline, elle aurait pu identifier le réseau d’une autre manière.
Voici comment je suis arrivé à retrouver des sites en quelques clics. La première « erreur » vient d’un script inclus (bha oui, c’est quand même le titre de cette section).
Il me permet de récupérer déjà pas mal de sites (230 pour être exact).
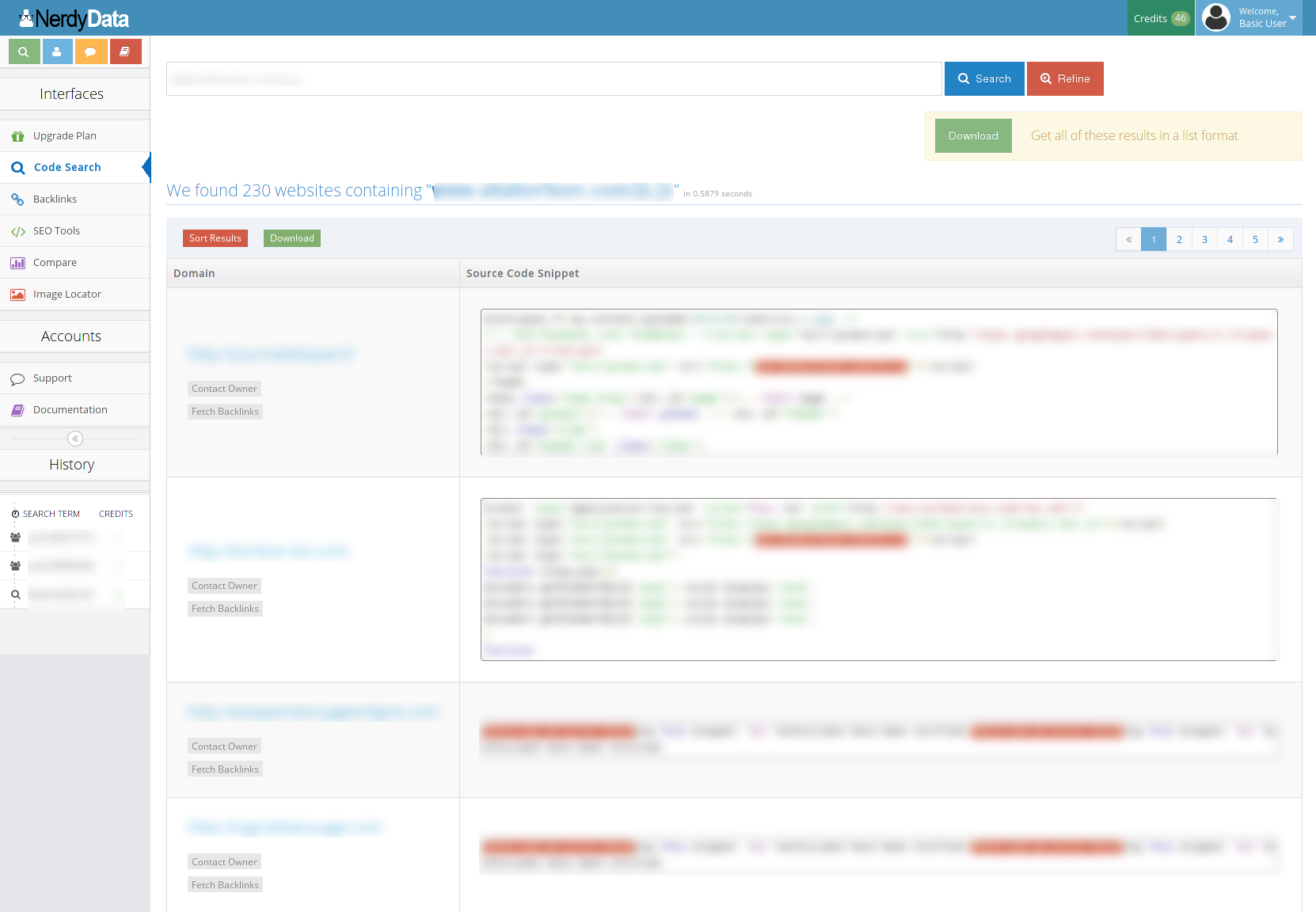
Pour aller encore plus loin, il suffit ensuite de scraper chaque site, de récupérer les status code pour vérifier ceux qui sont en ligne, de récupérer les id adsenses, de dédoublonner et de retourner sur nerdyData pour obtenir les résultats. Voici ce que j’obtiens par exemple pour un id (59 résultats via nerdyData, contre 50 via SpyOnWeb) :
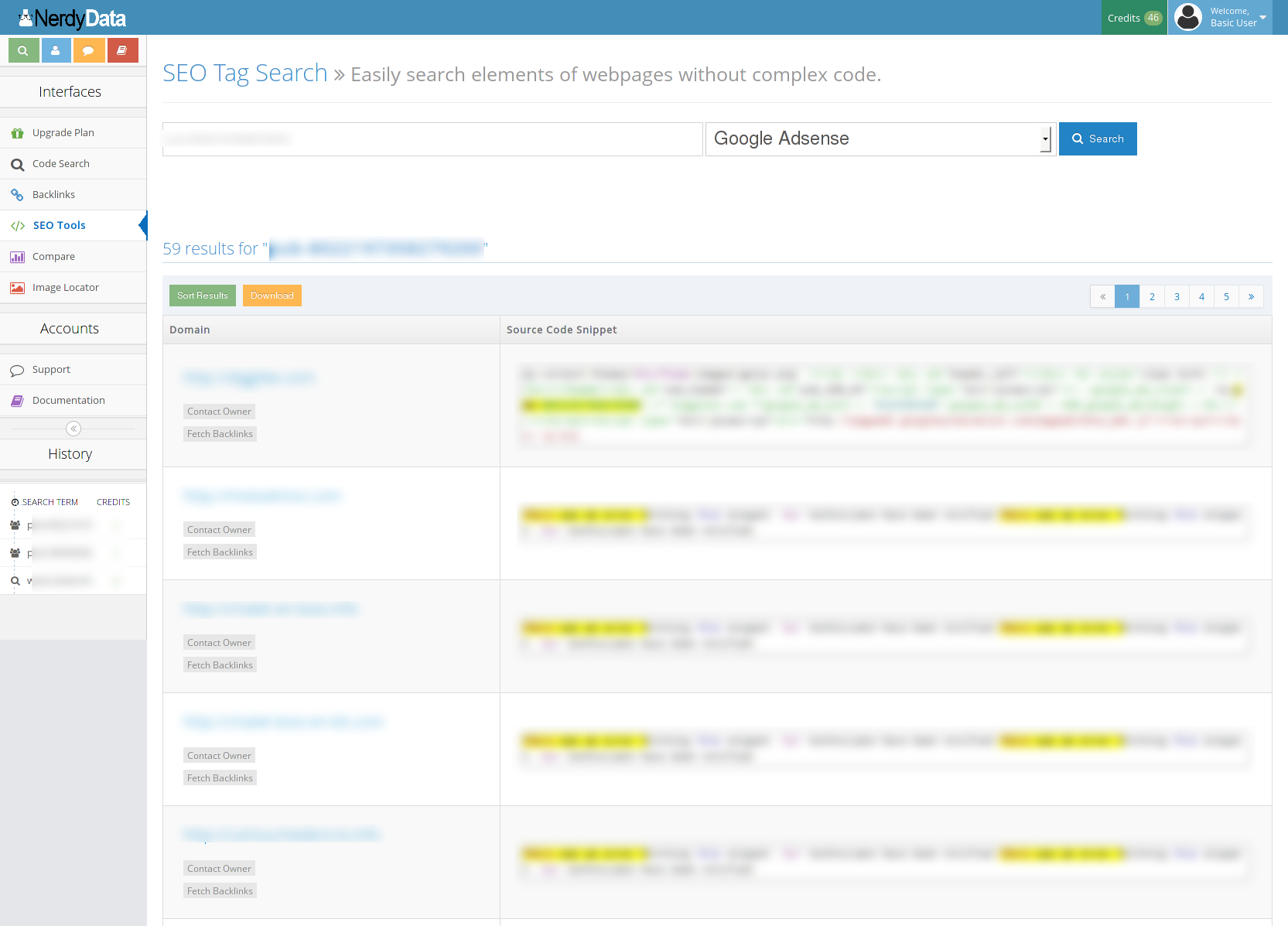
Conclusion
Tout d’abord, je tiens à souligner que je ne veux pas faire la morale sur la bonne ou mauvaise gestion d’un réseau de sites. Ce n’est clairement pas le sujet de cet article. Je souhaitais juste donner plusieurs pistes aux personnes qui gèrent un où plusieurs réseaux de sites et qui souhaitent cloisonner au maximum. Il suffit parfois juste d’un petit oubli pour obtenir plusieurs sites d’un réseau. Keep it in mind 😉
P.S. : Pour ceux qui souhaitent savoir comment bloquer le bot de nerdyData, voici la marche a suivre : http://nerdybot.com/ (et préférez le .htaccess au robot.txt :))
22 réponses sur « Comment identifier un réseau de sites »
Belle démonstration, par contre je ne suis pas sur qu’avec cette méthode tu puisses retrouver la totalité d’un réseau :)!
Je te Skyperai un de ces 4!
Sympa NerdyData, je ne connaissais pas 🙂
Personnellement je suis en train de consolider mon réseau de sites (+ de 100) et c’est beaucoup de travail que de le rendre invisible…
Tu peux cacher une installation Piwik avec ça : https://github.com/piwik/piwik/tree/master/misc/proxy-hide-piwik-url
Autre moyen de démasquer un réseau : les backlinks. Beaucoup de webmasters font des liens entre leurs propres sites au lancement d’un site, souvent les premiers liens obtenus sont sur le réseau du webmaster 🙂
A+
Je n’avais jamais pensé à tous ces détails, c’est vrai que de monter un réseau de site peut facilement être repérable, les solutions que tu proposes sont pertinentes.
J’ai mis ton article dans mon marque page, j’ai pour projet personnel de mettre en place un réseau de blogs, tes conseils sont très bon à prendre!
Merci à toi, à bientôt!
Quel est l’intérêt de cacher un réseau de sites à Google ?
Si tous les sites ont des contenus similaires, qui expliquent la même chose mais rédigé autrement, ça se comprends bien évidemment.
Mais dans le cas où le réseau est composé de sites complémentaires je pense qu’au contraire il faut lui montrer qui vous êtes en tant que webmaster (et auteur) et que vous êtes un expert dans ce domaine.
intéressant, et attention aux données soit disant cachées aux whois via une option payante, sur ovh par exemple ça marche pas, c’est privé sur certains whois et sur d’autres on retrouve tout.
un autre aspect dont tu n’as pas parlé est le linking du réseau, les spots en commun c’est le truc à pas faire si tu veux vraiment pas que tes sites soient dévoilés.
le moteur de recherche de code source, c’est top. qwant avais promis un truc du genre mais perso j’ai rien vu venir, d’autres à conseiller ?
A priori Netcomber est plutôt bon pour remonter les réseaux. Il ratisse large. Par contre il lui manque le minimum d’IA pour que ce soit parfait !
Google étant registrar, il est certainement capable de connaître les infos du propriétaire, même si elles sont cachées.
Puissant nerdybot.com : il m’a même -bizarrement- retourné des NDD en 301 (qui n’ont jamais eu le footprint d’adsense que j’ai recherché)
De tête Qwant est en train de préparer la même chose.
RDDZ, tu as oublié de dire qu’il ne fallait pas utiliser Google Chrome 😉
@korleon
Je ne pense pas non plus qu’il soit possible de remonter l’integralité d’un réseau. Mais tu pourras en retrouver une bonne partie.
Pas de souci pour le Skype.
@Julien
J’ai en effet oublié de parler du profil de backlinks, qui est également un bon moyen pour identifier un réseau.
@Sejourning
Merci 🙂
@Light on seo
Comme l’a souligné Julien, il est vrai que le profil de linking est également important dans l’identification d’un réseau. Pour le whois, c’est également vrai, après tout dépend de l’extension 😉
Et pour le qwant source, je sais que l’équipe en avait parlé mais je n’ai toujours rien entendu à ce sujet. Wait and see …
@Seo lyon
C’est exactement ça, Netcomber ratisse large (un peu trop des fois d’ailleurs) 🙂
@Fabien Branchut
Tout dépend de la manière dont le registrar cache les infos. Je ne pense pas que Google puisse accéder à toutes les infos …
@Jerome
Pour Qwant on attend l’annonce. Je suis curieux de pouvoir tester la bête quand elle sera dispo.
Et pour chrome, bonne remarque, le petit soldat de Google leur communique beaucoup d’infos 🙂
bon article, je regrette juste le manque d’une petite intro sur les reseaux, leur intérêt, et pourquoi chercher à les démasquer.. S’ils ne sont pas nuisibles individuellement il est peut probable qu’ils le soient en reseau.
Belle démonstration, je retrouve des sites persos dont j’avais oublié l’existence…
Comme Fabien, j’avais entendu (ou plutôt lu) que les whois anonymes étaient une illusion.
Vu l’ensemble des paramètres à gérer, je préfère lâchement penser que Google est plus fort que moi et être totalement transparent (cf la conférence de Keeg sur les réseaux de sites en décembre 2012 au SeoCamp).
En tous cas pour avoir lu l’histoire de Julien et qu’il donnait des accès à ses spots par sincérité, ça fout fichtrement les boules de voir son réseau se faire décimer par un ou une bande de jaloux/vilain.
De quoi être parano et tout cloisonner, sécuriser son réseau de site…
Rendre intraçable un réseau de blog est une tâche à réfléchir en amont bien évidemment. Il faut penser à toutes les solutions à mettre en place, applicables sur tous les futurs sites pour que ce soit efficace. Les différents points que tu nous présente dans cet article sont très pertinent, je n’avais jamais pensé au WHOIS pour tout te dire!
Cela me donne envie de copier ton article dans Pocket, je prendrais en compte tes conseils, tout est bon à prendre!
Merci beaucoup.
Le ficher robots.txt aussi
Le nombre de sites satellites qui bloquent ahrefs, majestic, semrush etc… pour qu’on ne trace pas les backlinks et qui ont tous le même fichier robots.txt, c’est facilement grillable 😉
@Auvairniton : Il y a 2 stratégies possibles à mon avis. Soit on planque tout son réseau à 100% (mais on fait ça bien, avec faux nom, CB anonyme…), soit on est transparent à 100% genre « j’ai rien à me reprocher ».
Je crois que de tout façon il devient de plus en plus difficile de cacher quelque chose au grand Google aujourd’hui..
Je suis novice en la matière mais serais-ce une alternative à ce que propose google pour la suppression de donnée ?
Au lieu de supprimer, rendre intraçable !
Pour ce qui est des réseaux de sites je rejoins l’avis des autres, ton article est top et instructif on comprend pourquoi il est important de bien cloisonner son réseau de site et/ou blog.
Les réseaux de sites sont tellement la chose qui me fache la plus au monde. Plusieurs de mes concurrents le fond et je dois dire que c’est choquant!
J’espère à chaque mise à jour de google qu’il soit pénalisé.
Merci pour cet article très complet! Néanmoins je pense qu’il va être de plus en plus compliqué de passer inaperçu aux yeux de Google au fur et à mesure du déploiement des nouveaux algorithmes…J’espère me tromper
Bravo, super tuto !
Ila va être de plus en plus difficile de se cacher auprès de Google, le white hat a de beaux jours devant lui encore !
Je vais me pencher sur Nerdydata qui n’a pas l’air simple à utiliser…
Une folle envie de partager cet billet avec pas mal de contacts que j’ai dans le milieu qui manquent un peu de jugeote de coté là…
Rien qu’un whois permet trop souvent de repérer 4/5 blogs, sans compter les variations sur le même thème (immobillier-nomdelaville.fr qui existe en 5 ou 6 versions différentes avec le même template).
Bref, 100% d’accord avec ce billet, un bon réseau ça DOIT être correctement pensé et mis en place.
La classe nerdydata, c’est vraiment une machine de guerre, après faut en avoir l’utilité régulièrement pour prendre l’abonnement, mais en oneshot ça se test (si il était dispo dans un seo group buy se serait top 🙂